For someone who is into Minimalism & believes in Curating life, BIFL feels like a natural progression to get into.
I personally feel there is not enough literature for BIFL in India. But the traditional Indian philosophy has always been long term, high quality, bang for buck buys.
So here’s my compilation of items which I consider BIFL in all facets of life with a focus on Indian products as much as possible.
Philosophy
Apart from the idea that they should last long, there are some properties these things should usually have
Material over Brand : Brands ensure material sometimes, but materials triumph in the long term. A fancy high brand furniture will never outlast a solid wood furniture.
Repairability over features : Things should be easily repairable. Dumb is better than smart.
Picks for BIFL
Item
Preferred brands / materials
Cookware
Indus Valley for cast iron.
Hawkins, Stahl for steel.
Pressure cookers
Prestige
Dutch Oven
Le Creuset
Mixer Grinders
Preethi Zodiac
Glass Jars
Borosil
Knives
Victorinox
Furniture & Cupboards
Solid wood
Hand Tools
Taparia, Stanley
Almirah
Godrej Steel Almirah
Dumb bells
Flexnest dumbbell set or better, just the cast iron dum bell set
Water Bottles
Borosil
Jeans
Levis Jeans
Watches
G-Shock, Seiko automatic/mechanical
Coffee machine
Moccamaster
Luggage
Samsonite or American Tourister (High end lines)
Desktop PC
A custom built tower lasts really long (maybe pieces need to be swapped, but the unit will go strong for 10+ years)
Some notes
Layer project : Ironclad lifetime warranty. Looking forward to buy and test it out
Seki nail clippers: Japanese Nail Clippers, apparently you’ll never need to buy one more.
Nalgene bottles: Lifetime warranty. Need to check it out.
This is a work in progress document. Every line in this document goes through a lot of thought.
Alternative title: “On conscious living”
If not thought about deliberately, it’s very easy to just go along for the ride every day for hours, days and months without realizing that life is happening to us and not the other way around.
Especially in the current age, where distractions are rampant having a focus on conscious living becomes very important. Otherwise your surroundings, the media you consume and the people you follow will end up dictating how you live & where you’ll spend time on.
Curation is hence very important. Everything in our life should fight for its existence, since the very foundation of life, time. Is finite. If something exists in our life and does not make us happy or is unused for an extended period of time. Maybe we should deeply evaluate why we cling to it. Every principle, habit, every thing should be curated for utility and/or happiness.
Here is how & what I’m curating for my life
Clothes and other wear
Keep this in check, they seem to add up quickly. Clothes don’t seem to add happiness for me. I’ve given it a honest shot and am still of the same opinion. Although this is my target state, I’m far from it as of now.
Around 7 pairs of comfortable and plain shirts and pants for day wear.
10 pairs of night and home wear.
Around 10 pairs of party wear.
Around 5 pairs of ethnic wear.
Running shoes
Sunglasses
Travel towel and a 2 normal towels
Routine
Breakfast and filter coffee in the morning
At least seven hours of sleep. Sleep before 11:30PM.
Strength training 4 times a week
Cardio At least once a week
Travel
At least once week of conscious travel every quarter
One international trip every year, life is too short for limiting ourselves. We are fortunate to be blessed with some health and finances to be able to afford this
At least one trip inside India for around 3 to 5 days
At least one quiet trip where the target is to wind down, not run around
Physical Health
Yearly full body health checkup to ensure that there is no obvious issues
Have body fat percentage targets and achieve them in 3 to 5 months
Curiosity
Pickup unusual things and go for it, all in
Formalize Experimentation budget
Passions
Trekking: atleast one trek per year?
Photography
Home labbing
Writing
Watches
Self quantification
Wood working
Minimalism, one bag and BIFL (Buy it for life)
Reading
Mental health
Therapy
Media & Consumption
Podcasts
Movies and series
Creation
Write every week at least once
Passion projects: need to be focused and deliberate. Do maybe 3 per quarter but only let the ones survive which people use after 3 months of marketing. If it does not take off after 3 months, kill it.
Wealth Management
Keep it simple
Invest when salary hits your account. Equities heavy portfolio for now, and a good allocation into index funds
Get portfolio & plan for FIRE reviewed by CA periodically. Figure out diversification & be smart about the plan (maybe this should be moved into routine)
Work
Focus on growth, be selfless. Make everyone around you grow as much as possible. A raising tide lifts all boats.
Upskill engineering wise, attend the next system design cohort. Go to a couple of engineering retreats. Go to engineering meetups to network. Focus on growing your moat.
Electronics
It’s funny how fast these things grow in size if left unchecked. Throw away everything apart from
Phone
Laptop
CPU
65W charger
Type C to Type C wire
Type A to Type C wire
Type C to lighting wire (for airpods)
Lauv mic
Condenser mic
Soundcard
Monitor
Wireless earbuds
Headphones
Watch: a automatic & a smart watch
Kindle
Powerbank
Wireless / bluetooth mouse
Wired mouse
Bluetooth speaker
Two gaming controllers
HDMI to HDMI cable
HDMI to Type C cable
Ethernet cable
Principles
Principles are decisions taken at bulk preemptively. The more principles you have, the lesser you’ll have to think for small things day on day.
A lot of people don’t think about principles this way, but eventually arrive here in terms of output. Everyone has principles, some think about it explicitly. It’s just a matter of preference.
Here are mine (Again, heavily WIP)
Be kind, to everyone & everything
Take & evaluate feedback, who gives the feedback is irrelevant
Teach at every opportunity. I’m here because of some great teachers online & offline. I should give back.
Invest every month as long as there is excess after routine monthly spends
If it can be afforded, prioritize saving time. Mental peace & convenience over saving money
Get world class, high speed, voice to text based typing systems to Linux.
There is nothing Super Whisper for Linux. The idea is very simple. You have a simple application which triggers on a keyboard shortcut and converts speech to text and pastes the text in the window in focus. So that instead of typing, you can just talk.
The Why
It is said that the average type speed is at 60-80 wpm and with voice we get up to 120-140 wpm. That’s a pretty good win. Voice based typing should have been a lot more straight forward but unfortunately its not. When whisper came out, apart from subtitles auto generation the other thing I was genuinely excited about was speech to text for typing.
Interestingly, this is not a solved problem yet on our phones. But on macs, it seems to be a solved problem. There are a plethora of choices for STT (speech to text) for typing
are some of them. You’ll find people developing apps all the time for this and selling lifetime subscriptions.
Life time subscriptions usually because they do the transcribing on machine.
You’ll also see them talk about a minimum system requirements of apple silicon. I think with apple silicon, its not really hard to run Whisper or Parakeet locally.
But then on my measly thinkpad linux system, there is neither apple silicon or a GPU. So I’ll have to make do with slow transcription if I do decide to run everything locally.
Anyways, I thought I’ll fix this by creating Speechshift. A CLI tool to run in linux so that your voice can be used to type at the speed of talk.
Whisper is not that great for audio transcription
Whisper was released in 2022. Its been a while, although it does not feel like it. Whisper base & tiny are very bad in terms of transcription, although they are amazingly fast.
To get quality, I think we need to use the medium or the large model. But the problem is that the medium model 1 takes time to execute, 2 is fairly heavy, so the transcription speeds are very low. It will take a lot of time to process very little text. Not a great experience. The higher up you go, the accuracy goes up, but then the time also goes up, so it doesn’t work. There are other models by Nvidia which seem to perform better. I’ll need to test those.
Pre-processing for audio
With Whisper. One of the problems is that we need to do a lot of pre processing of audio before we decide that that audio file can be passed to Whisper. Two very important stages of audio pre processing we’ll have to do is VAD & normalization.
VAD stands for voice Activity detection. The idea is that it tries to figure out whether voice in the audio and wherever it does not find voice it will effectively remove that part. That will make sure that Whisper processes lesser audio and correspondingly has a performance boost. The other one is normalization where you strip off all the higher and lower frequencies so that unnecessarily audio data is not being passed to Whisper.
These are the two things I could figure out. I am sure there is more to do in this segment to make sure we can squeeze the most performance out of Whisper, but right now this is what we are doing. Things tend to be slightly better but there is a lot of scope for improvement.
Perception & UX
We seem to have a very low tolerance for how much time we allow a process to run. If a transcription of say 100 words takes 5 odd seconds, it feels very slow still, so having anything above three seconds is usually a bad idea UX wise.
Making sure that transcriptions happen under 3 seconds is going to be an absolute challenge. Local models tend to perform very slowly on weak processors in the absence of graphic cards, and that is something we’ll have to live with until better CPUs come to everyone. Even online services tend to take a bit of time to process audio. Since I don’t have a very powerful system, I thought I’ll move to the online transcription services, Assembly AI being the most popular one. But assembly AI also seems to take quite a bit of time to process small amount of audio, and that lag tends to be very irritating.
One more issue is that, I am running the entire system as a daemon. In the Linux system in the way you trigger a recording is by pressing command shift r and the way you end the recording is by pressing Command shift R. There is no real way to cancel a recording midway. This is a feature I will need to implement as soon as possible because this is a very normal requirement. But right now, as a function of not having a UI, there is no way to cut a recording midway.
Omarchy is an opinionated Arch + Hyprland Setup by DHH. DHH is the guy behind ruby on rails, co-founder of basecamp and many other things. I seem to agree with most of his opinions and am interested to get into ruby because primarily he is a big proponent of ruby. Ever since I heard he migrated from Mac to Linux and started the Omarchy project, I thought I’ll check it out.
First opinions
Omarchy is hardcore but approachable. That’s high praise.
Hardcore because you are still dealing with a tiling window manager laser focused on keyboard based navigation. So you’ll have to train that muscle. To start off, you need one keybinding. Command + Space. It launches the Omarchy menu. You can install, update, configure Wifi, Bluetooth and a lot lot more from this menu. This is really well done. This is core to what makes the OS approachable.
Omarchy also says that its meant for developers. So almost everything is a TUI (terminal UI). Want to setup wifi, TUI. Want to setup monitors, TUI. Do I like it, no. Should I learn syntax to do something as basic as changing the display resolution for my monitor, yes. Will I do it everyday? No. So does it matter that much, Nope.
Now a days, all it takes is a query in Claude to figure out how to do something. So its not really that hard to configure something. That being said, some of this could be more “Obvious” (I know that’s a loaded term, but hear me out).
Some pre-requisites to understand
DHH is a man of taste. It does not matter if you agree or disagree with his taste, its worth appreciating when someone has sound taste and work towards creating a world which adheres to their taste and shares it out in the open.
Second point, DHH really believes in beauty & aesthetics. Aesthetics is why he picked ruby as his primary programming language. In his Lex friedman’s interview, he mentions why he likes ruby and quotes an example of the ruby syntax `5.times` and how it just beautiful. I gotta agree, I’m a python aficionado usually, but man, it is beautiful. Isn’t it? I should spend some solid time learning ruby.
Now, I am also an aesthetics guy. I love obvious stuff and great design. So, I’ll be slightly critical here and there. But all of this is in good faith and I’m sure Omarchy will change for the better.
With this context, let’s talk about speed breakers.
Speed breaker: Configuring monitors
I understand Omarchy is limited by hyperland’s configuration language etc.. But configuring monitors is .. interesting.
You are supposed to write a line in a configuration file that looks like something like this
monitor=DP-2, 3440x1440@144, auto, 1
What I really would have liked is to use something like Hypermon. Wifi has a beautiful TUI, Hypermon would be a beautiful TUI for monitor configuration I believe.
Speed breaker: Laptop lid close after connecting to monitor keeps the laptop display active
I like to think a lot of developers have a setup where they connect a monitor, keyboard & a mouse and just use. Laptop lid close usually just disables that display and moves the rest of the windows in that workspace to the other workspaces. This is usually a very common behavior which all operating systems support at a box. For some reason it requires a good amount of work in this particular setup.
Once that’s done, then on laptop lid close the laptop display is switched off. Which will automatically move windows around etc..
Note that there is one catch with this. If the system starts off with laptop lid closed or you reload the desktop environment with the lid closed then the laptop monitor will switch back on because there is no laptop lid event to switch it off. Hopefully there is a better solution to this, I will iterate on this later sometime.
Speed breaker: Nothing like superwhisper
One thing I’ve been used to when I was in a Mac world was SuperWhisper. It is a simple application which transcribes voice to text. It has been very useful for me to write long-form blog posts, write prompts for kilo code etc.
Unfortunately, there is nothing like it on Linux. So, it’s a good time to start a new project, and I started a project called SpeechShift, which effectively takes voice and converts it to text and pastes it in the focused text box. Check it out, its already published on Pypi as well
What I’m enjoying
Apart from this, learning keybindings is work but then once you are used to it, it changes your life. So my suggestion is to stick through it and learn.
Installing and removing software is a breeze. The command + space menu is very well thought out and I think this is a beautifully well done setup.
Closing thoughts
I’ve been using a mac for a good 3 years as of now (before which I was using fedora on a thinkpad). My primary workhorse is a macbook, I think that will continue.
Macbooks have a dangerously good combination of insane battery life, great keyboard, solid build quality, extremely high performance processor and a decent operating system. So its very hard to find hardware at the same caliber for linux, so primary workhorse will still be a macbook. But whenever I’m working out of home or office, I think I’ll stick with Omarchy and see how it goes.
I think it’s high time Linux — and operating systems like it — had a capable agent powered by an LLM (for example, Claude) that can:
change configurations safely (along with rollbacks),
educate users and answer questions,
help onboard new users to the OS.
The learning curve is still a speed breaker; an integrated OS assistant that teaches skills and guides users through common tasks would make adoption much easier. Maybe this is an opportunity for me to do something here 😉
TLDR: Our trip was for 14 days, we think it should have been double of that. Vietnam offers so much to experience that 14 days does not do justice. That being said, this was an unforgettable trip.
Pre travel
Get your visa sorted, the application form is slightly tedious but the visa is usually processed in three to five working days.
Convert and keep dollars handy. No one seems to accept cards without a surcharge. Which is usually three percent. There are a ton of places with no support for cards since they don’t even have a card machine. All the tickets to the local sight seeing only take cash. Cannot emphasise this enough. Carry extra dollars and keep them handy for emergencies. We made a mistake here.
Limited vegetarian food options, very small number of Indian restaurants. You’ll also find a lot of vegan restaurants, but they too tend to be expensive. Food in the Indian restaurants does not really taste close to any Indian restaurant. If this is important for you, carry some pickles or something along that sort. Vietnamese cuisine is pretty bland when compared to Indian cuisine. Some day to day essentials for us like ghee and coconut oil for hair are not available anywhere as far as we searched for.
We suggest downloading
Google translate: We could not find a lot of folks who speak english in Vietnam
Grab: For booking cabs and bikes
Currency converter
Flighty on iOS: nice flight tracking with live activities and many other nifty features
Klook: For booking activities
12Go: For booking travel of all sorts (trains, cabs, limos, buses etc..)
Get your guide: For exploring & booking activities
While booking rooms in cities, room size becomes very important. Make sure you are booking good room sizes. At least 250 sq meters or above is recommended.
No windows in rooms is a thing, make sure your rooms have windows if you need
If it’s a long trip, plan carefully and have a laundry day. Laundry is not super expensive and is well worth it. 50k per kg of clothes. A kg of clothes is lesser than you imagine. But still worth it.
No one in Vietnam gives free water. Not sure why. Make sure you carry a couple of steel water bottles and keep refilling them whenever possible. Buying water can get pretty expensive.
For domestic travel, try exploring options across trains and buses. Trains for domestic travels is an extremely good option. The prices are extremely reasonable and they tend to be pretty comfy too.
Small travel hack, if you don’t select seats during booking, a good chunk of money can be saved since the airline auto allocates free seats. You usually end up getting seats side by side at the end
Luggage weight is a big pain, make sure you measure and travel
Wherever the place is famous for history, try taking a guided trip and make sure the guide knows English. It makes a big difference if you see the site through the story in the past.
You can explore buying electronics & food in Vietnam, especially macbook products. You’ll also get a VAT refund (of around 8-10%) which you can claim at the airport. VAT refund only works if the package is unsealed. If the item is consumable, then make sure you have proof that it’s not consumed: if it’s supposed to in check in. Make sure that you go to the VAT refund office before security. Else after security is preferred. Make sure the shop is giving a document which is also uploaded to the government. The VAT refund folks will give back USD.
Renting a bike is always a good idea. Grab can get pretty expensive. No requirement of an international driving license, you can either have a deposit of three million VND or deposit your passport. Which we found to be safe. Driving in cities is a bit hard since Vietnamese are super good at driving their two wheelers. If you are a novice driver, I would not recommend driving in cities.
If you are open to buying and getting some local produce from there, make sure you incorporate visiting markets during your travel. Here are our recommendations
Fabric (silk specifically) in Hoi An
Coconut candy, Fresh coconut oil, Royal jelly and pure honey in Hoi An
Skin care & beauty products are pretty cheap everywhere
Dried fruits (like mango)
Coffee (ofc)
Last but not the least, don’t pack your trip too much. It can get hard to breathe if you are jumping cities every two days. Make sure you have three or more days at least per stop, otherwise the trip will get suffocating.
Our Itinerary
Day One – HCMC & Settling into Vietnam
Arrived in Ho Chi Minh City and settled down. First steps: rented a bike, converted USD to VND at a forex center, and got a Viettel SIM card (better to buy it outside the airport). Downloaded offline maps to stay covered even without network. Visited Bùi Viện Street — busy and lively. Also stopped by Book Street, where we got a hand-painted postcard. The painting wasn’t great, but it’s a nice keepsake.
Day Two – Mekong delta tour
Took a Mekong Delta day tour. The landscapes were stunning — lush greenery, serene waterways. Would suggest picking up royal jelly, honey, and coconut candy from local vendors
Day Three – Da Nang
Flew from Ho Chi Minh City to Da Nang. Rested at Mỹ Khê Beach for a bit — peaceful spot. Visited the Lady Buddha Pagoda — beautiful and very calming, definitely worth seeing. Stopped at Bye C Café, a gem in Da Nang. Highly recommend trying the shakshuka, berry smoothie, coconut coffee, and French toast here. Ended the day exploring Son Tra Night Market and another local market — if you bargain hard, you’ll walk away with great deals.
Day four – Bana hills
Visited Bana hills. Cable car is great. A lot of french inspiration. A lot of backdrops for instagram worthy photos & they’ve tried to mimic dubai miracle garden to some extent. Good fun. Alpine ride is must do activity! Highly recommended. Golden bridge we felt is not really worth the hype. It seems to be pretty crowded all the time. There was one museum about jurrasic fossils and life size dinosaurs & mammoths. It was very nice.
Day five – Citadel & Tombs in Hue
We travelled from Da Nang to Hue on a train. The travel in the train is very beautiful. You can see a lot of mountains and water bodies from the windows. They even have a cabin where you can see local vietnamese dance and have nice coffee in the train!
Citadel is worth two to three hours of dedicated time. You’ll need that time to soak in the rich history of vietnam rulers, the grandiose lifestyle of the royal family and the art. The palace grounds are very vast. We would also recommend an audio guided tour since its easy to go in circles. This place really blew us away, highly recommended you do this first.
The rest were not so great in our opinion. Hue was one place which seemed pretty expensive. When we landed the first place we explored is Khai Dinh Tomb. The entry pass was 150k VND per person and the place was pretty vast. But we did not feel it was worth the 150k or the time investment. Apparently Khai Dinh was also a bad ruler who invested a lot of public money on the tomb itself before his death. Seemed off. We did not seem to enjoy tombs much, so we skipped Tu Duc Tomb.
Then we went to the incense sticks village. It was stunning, the entire setup was beautiful. They expect you to pay 20k-30k VND to take a picture with the incense sticks backdrop. Instead we would suggest you to buy some incense sticks and get some pictures, you would also end up supporting the community.
Then we went to Thiên Mụ Pagoda. There we also saw the car driven by Thich Quang Duc. He was the buddhist monk who drove to Saigon & self immolated as a protest against the Diem government.
Post which we went to The garden cafe, where we had both our brunch add dinner. Very hospitable folks and the two dogs they have are lovely.
Day six – Cooking class and Riverside in Hoi An
This day from Da nang we travelled to Hoi An on bike. We passed marble mountains without noticing it. We would suggest you visit marble mountains while going to da nang.
Once we arrived to Hoi An we went to Minh Hien Vegetarian Restaurant for lunch. The food was good here. We tried the cooking class here as well, the chef did not let us write the recipe down or record the session. Each person did not get a cooking station. All three people who were in the session had to watch and do parts of cooking. For the price it was worth it (we paid 700k VND for the class alone, skipped the market tour). But there are other cooking classes which are slightly more expensive (near about 1 to 1.2 million VND) but do better in terms of setup and notes.
After this we went to the river side where everything is nicely decorated with lanterns. There is a lantern boat ride in the river, they seem to have two options. A large boat and a small one. Since we are a couple, we picked the small one. The concentration of lanterns is better on the small one we feel. We would recommend picking the small one. They would also hand you a couple of paper lanterns which you yourself can float. The ride was very beautiful, worth every penny.
In the market near the river they have lantern shops which make a good backdrop to get some pictures. They usually charge 10k VND per person, we would recommend it since the pictures are stunning.
In the river side, there are bars and live music. Its worth to just grab a chair and sit on the riverside while you sip your drink. Lenco cafe is also good to chill.
Silk here is really high quality in Hoi An. Everyone across Vietnam would suggest getting fabric and clothes tailored here.
Day seven – Marble mountains & lantern making in Hoi An
In the morning we set out to travel to marble mountains. We rushed this a bit but the caves were humongous and very well maintained. Post this we set out to go to lantern making.
We took a lantern making class at Hang Dung Lantern making class. I sticked fabric and made a lantern and my wife painted on a lantern. The hosts here also were very nice and we made some good memories.
Day eight – Settling down at Hanoi
We now travelled from Hoi An to Hanoi. This was a bad day for us, the homestay we booked was not that great. The rooms apparantly in Hanoi are extremely small. Especially in the city center. So we decided to take a refund and start searching for another place. This ate away a lot of time unfortunately. Post which we did not have a lot of energy to explore other parts of Hanoi. So that night we just relaxed next to Hoàn Kiếm Lake and got back to the hotel
Day nine – Ninh Binh tour
We booked a tour and went to Ninh Binh. This place was absolutely gorgeous. We highly recommend booking a tour because you’ll also get a guide who will explain history. We first went to the tomb of the first emperor and other temples around it. We were lucky enough to also get to see a local Vietnamese celebration.
Post this we went out for the boat ride. The boat ride was unforgettable. The vast green landscapes, the caves we pass through, the serene atmosphere. Everything about this was perfect.
Next we went to the dragon mountain. This is what you would have seen a lot of drone shots on social media. The hike is pretty demanding but the view from the top is worth it. The hike from the dragons head to tail is pretty challenging. Please make sure you wear good shoes so that you can experience this well.
Day ten – Ha long bay cruise
We booked a Ha Long Bay cruise which we started for. The cruise was quite expensive, so we were curious on the experience and looking forward.
Ha long bay was stunning, the cruise took us first in Tip top island & took some pictures. The day was ending the cruise folks had a part on the deck of the ship for the night. It was a night of dancing and drinks. The host was awesome and the experience was fantastic.
The next day we went to the surprise cave. Again a tour guide could potentially be nice because they could show the cave formations which look like animals. After this we set out to do kayaking. This was again a very memorable trip cause of the views. The cruise was well worth the investment. We would recommend it any day.
Day Eleven – Sapa
We took a bus and went to Sapa post the cruise. Since the trip was super loaded, we decided to lay low for a day. That night we went to chicago pizza and had a deep dish pizza. It was great. After this we just slept for the day and prepped ourselves for the next day.
Day Twelve – Cat cat village tour in Sapa
We started to cat cat on day twelve. This was a small village where with some waterfalls, a good market, a place for local Vietnamese art performances etc.. It was a good trip.
Day Thirteen – Batarang
Now we started to Bata rang. Its a village famous for ceramics. The market is pretty mind blowing, especially the 6-7 feet vases.
We bought a tea set, two bowls, a cup and some other small ceramic stuff from here. The travel from Hanoi to Batarang is around 45 minutes. The visit was well worth it.
Day Fourteen – Travelling back home
We relaxed in Hanoi and got onto the flight back to Bangalore.
Some food recommendations
If there is a chance of missing some home food, highly recommended to carry some pickles dry food items and nuts to have when you go.
deep dish pizza in Sapa (Chicago pizza)
Curry in coconut is a must in Sapa (reminds you of Kerala or coastal stew of India)
Maazi across Vietnam had decent food
Baba restaurant in bue vienn street HCMC was good (after all the Vietnamese food you get to eat papad and pickle as complementary, which you’ll relish)
Hue cafe
Hoi an cooking class place really good food
Must try dishes: specially for Indian food lovers – papaya salad, spring rolls (I loved fried, but if you like to feel light do relish the fresh spring rolls)
Monitoring and logging in large companies is a critical aspect of system management, as it helps track the performance and health of applications. A popular practice among some organizations involves using a common data store, usually a time-series database like Elastic, to manage metrics as logs. This setup, often utilizing the ELK stack, includes tools like Logstash.
In this system, almost everything is treated as a log. API latencies, metrics, responses from external APIs, and database queries are all considered logs. This approach is nice because it allows for easy metric creation, making it straightforward to set up alarms or dashboards on top of these metrics.
However, this is hard with untyped and loosely structured logs. Usually this is where a lot of companies start from. Logs often lack structure and can vary widely in size and field count. The goal was to transition our application servers to Elastic, allowing it to manage all logs while enabling us to build metrics and create dashboards based on them, accessible throughout the company. During implementation, we encountered issues with Elastic’s handling of mixed data types.
Elastic indexes and data types
Elastic requires consistency in data types for fields with the same key. For example, if the first log’s result is a number, Elastic expects all subsequent logs to adhere to this data type. This becomes problematic when different data sources, such as Cashfree, Razorpay, or Google, return varied data types.
Structuring Logs for Efficient Indexing and Debugging
Every log entry contains two key components: metric data points and debug data points. This distinction allows for both efficient indexing and comprehensive debugging.
Metric Data Points: Structured and Indexed
Metric data points capture well-defined, structured information that can be indexed for querying and analysis. For example, if an API call to Google fails, the log should record essential details such as:
• The API endpoint called
• The user ID associated with the request
• The error code or status
This structured data is stored in a predefined log schema, ensuring consistency across logs and enabling Elasticsearch to efficiently index and query it.
Debug Data Points: Contextual but Unindexed
Debug data points provide additional context but are not meant for indexing. These include verbose details such as the full API response, stack traces, or detailed request payloads. To prevent unnecessary indexing overhead, this information is placed in a dedicated field, such as _debugInfo, which is explicitly excluded from indexing.
Balancing Indexing and Debugging
By structuring logs this way, we achieve:
• Efficient querying: Metrics are indexed for dashboards and analytics.
• Comprehensive debugging: Debug information is available for troubleshooting but doesn’t clutter indexed searches.
• Scalability: Consistent log structures prevent schema conflicts and ensure smooth integration with Elasticsearch.
The logger library seamlessly integrates both metric and debug components, ensuring logs are both queryable and human-readable without unnecessary indexing overhead.
Suggested Logger Interface
In this world, there will be methods which are more targeted and structured to make sure elastic can run with ease.
// elastic expects a clean and consistent type so indexing can work well
export interface MetricData {
applicationEvent: Uppercase<string>;
logLevel?: LogLevel;
correlationId?: string;
apiName?: string;
count?: number;
entityId?: string;
errorCode?: string;
queryExecutionTimeInMs?: number;
// all data relating to debugging, this is not searchable on elasticsearch by design
_debugInfo?: Record<any, any>;
}
and then there will be a logMetric method which is strongly typed and will log this metric data out into a log stream. This is later picked up by logstash and pushed to elastic.
Setup a strong correlation ID system so that correlation IDs are neatly cascaded across the system, and also source correlation IDs are respected
Having an API name (this can be the name of the function of the controller) is very useful to breakdown visualisations for slow queries, server latency breaches etc..
Why? Because I want to budget so that I can spend more where I can and cut down where I have to.
Simple, right?
Before we start, let’s go through the lay of the land. I have one bank account (HDFC) & two credit cards (Amazon ICICI & OneCard) from where I spend.
I invest through Zerodha, but tracking investments is a whole new ballgame and I don’t want to get into that.
Now about spends. Pretty simple setup, whenever salary hits my DBS account (which I’m trying to retire), I transfer it to HDFC and run all transactions out of the HDFC. Depending on offers, I spend money on the credit cards if it makes sense & usually pay the bills in under 20-25 days.
About the transaction mediums
UPI for day to day: 80% of my bank statement is UPI spends (I’ve crunched numbers btw). Range from >5 to < 5000 INR usually.
NEFT & RTGS: for cross account transfer
ACH (Automated clearing house transactions): For all the auto deducting subscriptions, mutual fund transfers etc.. volume wise these are less transactions but amount wise they are significant.
First try: Account aggregator
Account aggregator in principal is awesome, one singular place where all account information is available.
But that’s the catch, it is available. But not to you. It is available to companies to profile and sell their business.
I have nothing against it by the way, making money is important. I would have loved if some company offers a paid API to pull transaction data so that I can setup everyday sync with the budgeting platform of choice.
This is not a groundbreaking idea, Plaid is a company which does it in the US, a lot of other apps like YNAB use for syncing transactions. But no company in India provides this as a service. And interestingly no company is solving for budgeting yet in India. Why not?
Since I don’t have access to my own data neither through API nor through CSV exports in the Account Aggregator ecosystem, on to the next try.
Second try: Bank statement parsing
Every bank worth its salt gives a CSV export, Right?
Not really (for example Jupiter money does not), but some banks do. For example HDFC does!
You can download the last five years bank statement in multiple formats ranging from CSV to excel to MS Money..?
Anyways, we need to download “delimited”, which is “delimited” by a comma. Nice. But on downloading you see a txt file…? How did that happen?
Well because HDFC only said it’ll share a delimited file, it did not say its a csv file. Right? so the text file is actually a csv file. You’ll just have to rename the extension.
On open, the first line is empty.. that’s not a deal breaker. But then you look at the timestamp, which is impossible because there is no time stamp in the export file. Only a date. So technically there is no ordering of transactions.
I don’t understand the rationality of these technical decisions for some reason. I’m sure the server is reading off a database, I’m sure it is storing the timestamp for reconciliation exercises. Why not share it? Is it because non tech people get scared by looking at timestamps? I don’t honestly know, anyways moving on
Now that the CSV piece is sorted, I quickly wrote a python script which parses and transforms the data into a simpler CSV. And then added another step to pipe it into Actual budget. My budgeting apps of choice.
I wanted to develop a pipeline where I can forward the bank statement to a telegram app & it parses the files and stores it in the budgeting app of choice. Because the whole notion of doing this every week on a desktop seems hectic to me.
So I open the HDFC mobile app, and go to the statement section.
On clicking “Request for a statement”, I realize that HDFC mobile does not have the option to generate a “delimited” statement. Only excel & PDF. WHY?
Alright.
I’ll write another parser for excel then, since its the only thing available for both mobile and desktop. Not a big deal, since the core logic is the same.
Side quest: Extracting data from narrations
See, Banks don’t give you what you want. They give you whatever they feel like. In a statement, it would be nice If I had columns as such
Timestamp
Payee
Credit/Debit amount
Mode
Payee identifier (could be bank account : IFSC, UPI handle or none for something like ACH)
Reference ID (Something along the lines of UTR)
Narration (for description/notes)
All of which is nicely laid out in their database I’m sure.
Payee context is important because If I have 50 transactions of swiggy, I need some way of saying that all of them are from me, the individual. To swiggy, the company without doing sub-string match kung-fu. I cannot really budget if I don’t know whom I’m paying to through my month.
But no, life can’t be that simple in Banking.
Banks just share
Date
Narration
Amount
Ref Number (UTR ID)
and that’s it! Now its my job to do sub-string match kung-fu and extract data!
What the **ck! (I was saying “what the heck” there by the way, messed up mind you got)
There is a way though, at least for HDFC narrations all UPI narrations start with UPI and delimited by – have the payee name, IFSC and narration. Similarly for NEFT and RTGS.
Sidenote, if you think the Ref number will be unique for all transactions. That’s not true. Some reversed transactions can have the same UTR (Unique transaction reference). One more thing to mention, if you have a mutual fund auto deduction or auto sweep setup for FD, then the reference ID can either be 0 (on CSV) or 00000000000 (on excel). They could have just let it blank, why have a variable length string of zeros?
Anyways. Moving on..
After dealing with all this, I wrote a parser in python through which works pretty well. So now I have payee information along with the narration. This later on becomes very useful since I can say that everything from Swiggy is food in my budgeting app.
But then, 80% of my transactions are UPI, right?
And all of them are small size payments done to local vendors. Normal people who don’t have a commercial entity… How do I know that I paid 250 to an auto guy for travel when 20 days back if the narration says “sidappa@ybl”?
Another side quest: Adding category context to UPI transactions
One solution is to type out some context in the UPI transaction notes section. say for example, enter “travel” when you are paying for auto and “groceries” when you are buying some vegetables on the street.
But the overhead of typing is pretty irritating.
So I thought I will make a react native app in which you can scan a QR code, put the amount, click on a category icon and click next. Meanwhile this app will generate a brand new UPI link with all this context and open it in your preferred UPI app of choice, with the description and amount pre-filled.
I’ve added one extra click to your user experience, but you are permanently putting context about transactions into your bank statements. That context is golden for budgeting.
I’ve actually built this out in about 2-3 hours, I’ll make it open source very soon. Generated an APK, checked it on a friends phone. It works! But it does not work all the time. Only merchant payments seem to work..
So basically, I scanned a QR code through the app. It made a new app link (something along the lines of paytm://pay...) and this opens paytm. The description & amount is as expected and right, but then after entering the PIN, the transaction fails stating “Risk reasons”.
On further research, I found out there is a parameter called signature. And it needs to be generated via authorized sources. normal links will not work.
Apparently, this is a known issue. And as of now without integrating with phonepe, cashfree or the likes, there is no way to go about opening UPI apps from my app. 🙁
I cannot even type the context manually since these QRs sometimes come with default transaction note, which cannot be over-ridden.
My current setup
Every weekend I block 15 minutes to
download the “delimited” bank statement from HDFC website, rename it to csv
use my script to extract payees where-ever possible, and generate a clean version of CSV with columns of my choice
send it through a data importer so that they get populated in my budgeting app of choice
With that, every month end I know how much I spent where. Also every once in a while I look at how much I’ve allocated for myself this month and see if I’m exceeding that. If yes, I cut down.
So the setup works, but it sucks. There is no seamlessness at all. It’s riddled with manual operations. I don’t like it, but we don’t have Plaid or something similar in India.
My ideal setup is a platform that allows me to do all this in an app, right from setting budget per category per month. Allowing UPI transactions with tagging, rules to classify transactions & reporting.
Until then, this is our best bet.
Conclusion
Thanks for coming along the journey, if you liked this post feel free to share it with your friends too. If you feel like there is a better way to go about it, message on telegram!
That’s about it for this time, hopefully there will be volume two which is not so long and much more cleaner 😉
Chefs come back home and cook for their family and friends. They look forward to the cooking on the weekend, the “specials” with great excitement. It is a place where there is love & gratitude. No pressure to deliver award winning recipes, just a good meal with jokes and banter. I think there is something beautiful in that.
A lot of Software engineers seem to have gotten into this mentality where things have almost always become about scale. Scale in terms of users & scale in terms of feature set.
Once in a while it is good to just build for ourselves, to build for friends and family. Something which is personal, predictable, customized. Something which is minimal & clean. Not after money, not after popularity & fame, not after hype cycles. Just for us.
With the state of things in open source and AI, it’s much more easier to build home grown software. Engineers should get back to building things for themselves & friends. There is no guilt in building something which is just being used by a handful of people. And it is a testament to the beauty of the mature structure and ecosystems we have around us.
I’m into budgeting and tracking expenses. I think a lot about personal finance, have written my thoughts earlier too. But the thing is that all tracking operates on data. And getting data out of the silo in a structured format is pretty hard.
Account aggregator is supposed to be solving for this. But each vendor in turn again locks data inside their silo and make their app more compelling. Until and unless we build plug and play pipelines we can never really do well in terms of developing personal finance management apps which make sense I think.
I’ve recently started using Actual Budget for budgeting for me and my fiancee. Its a very nifty software which can be self hosted. Now the challenge is to get data from the bank to Actual.
Figuring out how to get data into Actual
Here is the idea. HDFC thankfully gives a CSV export option of their bank statement. If I can figure out how to get this data into actual using a library like ActualPy, then everything is sorted.
Note that I’m using HDFC account, based on your bank these details can change (or not!)
Parsing the CSV file
So step one is CSV parsing. Some catches during the process.
Some lines in the CSV file have more than the required 7 columns. usually because the narration has a comma in it.
Some times, the ref number / UTR field will have zero. A lot of software relies on a unqiue identifier. In this case, its better to combine narration, date and hope it stays unique. There is technically a possibility it won’t though.
There is one catch, Actual works heavily on payee information.
Parsing Payee Information from the narration
What does this mean? Here is a sample narration from the bank statement
This seems gibberish, but this is loaded with information. Delimited by `-`, the first segment is the mode of the payment. the second is the payee name, third is the UPI ID, fourth is the IFSC, fifth is something I did not really get. I’m guessing the last is the note sent to the UPI network.
There seems to be a catch. Sometimes to fit in information, the payee name is truncated. Not really sure in what exact circumstances the bank takes a call to truncate the payee name. Need to look at more data and figure that out. Similarly, NEFT & RTGS also follow a similar structure. So, parsing the payee information is actually fairly convenient.
With this, more than 80% of the transactions would be covered. But then there are other important ones
ACH narrations, ACH stands for automated clearing house. If you happen to have a recurring eNACH, or a mutual fund has to post returns back to your account you’ll incur a ACH line item in your bank statement. ACH narrations are interesting because I’ve seen multiple variations in my bank statement itself. Usually it is ACH followed by a C if its a credit or D if its a debit. then after a hyphen, there is text explaining the transaction followed by an ID of sorts (I guess?). Need to look into this more
Here are some examples
ACH C- SYMPHONY LIMITED FV-SYM0INT02024W ACH C- ITC LIMITED-2643579 ACH D- INDIAN CLEARING CORP-H5GGPYWT2R6R ACH C- IRFC LIMITED-TAX FRE-2418947 .ACH DEBIT RETURN CHARGES 230124 230124-MIR2403472992640 ACH C- LTIMIN INT 2024 25-354851
Currently I’m not setting a payee for these transactions in my personal setup.
Streamlit is a framework in Python meant to turn data scripts into web apps in minutes. If you think about it, many apps are fundamentally data scripts first and web apps next. There are many scripts I have which would work better as simple web UIs.
I’ve been exploring how to get from idea to deployment quickly for a while. Of course, the answer is going to be slightly nuanced, but this approach works well for many simple and/or internal apps.
I recently launched CleanMail, which was actually a simple CLI tool back in 2019 called mail-sanitizer. However, it was using Google API credentials and was fairly inaccessible. Now I’ve moved it into a Streamlit app and deployed it on my Coolify instance, and people are using it frequently. I’ve also started migrating my scripts over to Streamlit since it’ll be easier to manage.
Here are some lessons I’ve learned while developing apps in Streamlit:
Embrace Forms
State management is hard, especially when there are no frameworks to rely on (like Redux, etc.). There is a lot of temptation to have independent elements in the UI and to manage state by hand. This will almost always end up being a bad idea.
Forms also control re-renders, and manual state management usually ends up being a pain in terms of the dreaded “Running” state, which kills the UX for the end user.
Minimize State to Manage
Forms help with this, but since there isn’t a lot of tooling around Streamlit right now, it’s important to minimize potential data present in state. Managing state and especially dependent variables in state is very prone to bugs.
Make Use of Fragments
Re-renders are time-consuming and sometimes irritating. Making use of the st.fragments API means that we can control the effects of state with more granularity. This becomes very important as the app scales up in logic.
If you haven’t used the st.fragments API, please do read about it. It’s quite handy.
LLMs for UI
Once all the core logic is in place, asking Aider to come up with an initial draft of UI is extremely useful. The first draft is surprisingly good and almost always close to what you would want in the end version.
Missing Components in the Ecosystem
Streamlit is awesome for a particular set of apps, but there are some critical components missing in my opinion. These are ordered by importance in my perspective
Library for easily installing analytics like plausible, clarity etc..
FYI, When I say OSM here, I mean the ecosystem of apps along with the core project. Not just open street maps website.
Let me start off by saying that Open Street Maps is a fantastic project helping a lot of people & organizations day in and day out. There is no doubt about that at all.
This is intended to be a review as a normal user & viewed from an angle of it replacing google maps eventually. I do understand OSM is a database first, but for the ecosystem to mature we’ll need a lively data source.
I’ve also been contributing to OpenStreetMaps, all the while pondering over how useful my contributions are (very similar thoughts to this post). As a contributor, to drive contributions it would be great to see a wall of fame for OSM.
But anyways, here are my thoughts on the ecosystem of OSM as a consumer looking for an alternative to google maps which uses OSM
If you are an iOS user, I would recommend using Organic Maps. Other alternatives include OsmAnd & Maps.me. If you are into editing the maps, I would recommend EveryDoor or Go maps!!
Extremely sparse Point of Interest data
The primary use-case as a maps user for me is to look up places like cafes, restaurants, pharmacies, ATMs, hospitals, parks etc..
Depending on where you are, this data is drastically out of date. Even popular places & parks are completely missing. This is mainly because OSM is community driven & there is not a lot of community in a particular place. This sucks from an end user perspective because this is the whole point of a maps for them. Roadways are also equally, if not more important but OSM seems to have good data around this.
Search needs a lot of improvement
This is probably the Achilles’ heel of OSM. In no app did I see a nice search bar with autocomplete ordered by relative distance popping up.
For example, from Andhra pradesh. If I’m searching for Catamaran (A cafe in allepy, because I just want to check open hours and call them up for some questions)
Organic maps: first result is Catamarca in Argentina
OsmAnd: no results
Maps.me : first result is Catamarca
Nominatim (the search powering openstreetmap.org) : One hit, the cafe. Bingo!
Some more examples, everyone is used to searching for “Cafes near me” or “ATMs near me”. None of the above apps show any ATMs around me if I run the same query.
This right here is what drives me nuts, consumer apps rely on search. Having a bad search engine is the single worst problem to have.
Missing user reviews, ratings with photos
This is not currently in OSM’s purview, understandably so. But there should be some integrations for apps like Organic Maps so that the quality of the place is evident. Say for example for restaurants, cafes etc..
A good web UI
A lot of times, I plan for trips and look up places on web. There is no good web UI for browsing OSM as far as I know.
Conclusion
I really want OSM to take off, I ran into OSM after knowing that Namma Yatri uses it extensively. Open data is core infrastructure and I strongly believe this should be open source.
But if someone in the ecosystem does not solve for this, we’ll never see the full potential of open mapping systems.
Talk is cheap, solutions?
Thanks for reading this far, I hope you see all this in good faith. I have a membership for OSM and now have a recurring donation. That’s my contribution on the financial side. Now let’s talk about the data side of things.
I believe more POI data is extremely important for more OSM adoption. I’ll start tackling that set of problems. Once the POI is setup, apps like every door, street complete and many others will start showing it on the app and people can start populating more granular data.
Here are some things I’m planning to work on or started working on
OSMRocket (alpha): a small app to take in plain text info on lat long, open hours, amenity from people and convert it to OSM tags setup. I’ve used this to add more than 50 places in my city. I found it pretty useful.
Scrape places with more than 100 reviews from google maps and make sure they are present on OSM. I have a script for this already, will furnish this as a project soon.
A good self host able search engine with proximity for OSM. Similar to OSM nomination. something which supports plain text also so that atms near me has results and is lightweight. Maybe host it and give it as a free service to organic maps etc..
An expo app which lets people click locate, speak into the mic and generate a osm card for poi using AI assistance. When pressed okay, adds it to a stack. Which will be later committed as a change set into OSM. A natural extension of OSM rocket.
What would be really be beneficial to the project. Most of the ideas here need funding, but solving anything at scale requires some capital investment
Google’s exhaustiveness comes from the vehicles which go around with high accuracy gps attached to 360 degree cameras and LIDAR for depth sensing. This data is later used to track roads, point of interest data and many other things. This is probably the only way to add seed data at scale. Once this exercise is done, people can later enrich data further. This is a high capital investment, but once data is in place it’ll prove to be very useful
Apple intelligence is slowly rolling out, meanwhile people are building their own versions of voice assistants similar to Alexa & Siri. I think its a good time to think about what prompts we can expect to work in a basic voice assistant, this might serve as a good test case repository to see how voice assistants perform.
This is excluding very basic prompts like
set a timer for 15 minutes
remind me to switch off the geyser after fifteen minutes
and many more. These are already well supported by most of the voice assistants out there.
Prompts
Set an alarm three hours before the flight departure tomorrow
Should read the calendar, figure out that a meeting invite for a flight is set to 9am in the morning. Set an alarm at 6AM.
Mark schedule visit to dentist as complete
Should query reminders, find out what’s the reminder about the dentist and mark it complete
Speed typing is the idea of working and improving on typing speed. It is said that an average person types around 40 words per minute (or WPM for short).
The reason I want to type fast is because I write a lot of blogs/notes. I don’t mind programming with a slower WPM since anyways that’s not the bottleneck. But during blogging, I would prefer if I can type at the pace of my thoughts.
People say typing speed does not matter in programming. I think that is not entirely true, if you are above 60 wpm I think you are good. If not, typing should not be a hindrance to think and iterate for programming is what my I think.
The journey to 100 WPM
My current baseline is around 50-70 WPM, depending on the tool. On KeyBR, I was told “Your all time average speed beats 50.19% of all other people. Average speed: 51.7 wpm”
Sleep is a lot more important than people think. Make sure you are getting a solid 7 hours of sleep every day.
Get a full body health checkup done start of every year. Get a doctor consultation to figure out an interpretation of readings and schedule top up tests depending on deficiencies.
Go get a routine ENT & dental checkup every year
Exercise at least for 2% every day, that is around 28.8 minutes.
Home assistant needs to run on the local network accessible so that devices can ping and communicate with it
Homekit integration will be using multicast DNS over 21063 (mDNS for short) to establish a homekit bridge between the server on the network & iPhone.
Since both Tipi & HA run in docker, we’ll need to install mDNS repeater on Tipi and use it to forward mDNS packets from HA.
It might look like a lot, but I promise it’ll be pretty straightforward. Feel free to contact me on twitter if you run into any issues!
Step 1: Configuring Home Assistant
First, we need to make sure Home Assistant is properly configured to work with HomeKit:
Open your Home Assistant configuration file (configuration.yml this is situated at runtipi/app-data/homeassistant-1/data/config/configuration.yaml).
Add the following HomeKit configuration:
homekit:
name: Bridge
port: 21063
advertise_ip: "192.168.0.101" # Replace with your Home Assistant IP
Save the file and restart Home Assistant.
Step 2: Setting Up mDNS Repeater
To ensure proper communication between HomeKit and Home Assistant, we need to set up mDNS repeater:
Identify your network interfaces by running docker exec <container_id> ifconfig , here the container ID is the ID of the docker container of Home assistant
run route -n to figure out what’s the network name of the IP address you got above
Install mDNS repeater app from runtipi appstore. Start the mDNS repeater with mDNS repeater app with the host interface (e.g., enp1s0) and the Docker network interface (e.g., br-fd25fefeed1f).
Step 3: Configuring RunTipi
Now, let’s configure RunTipi to expose the necessary ports:
Navigate to your RunTipi configuration directory: ~/runtipi/user-config/homeassistant-1/
Save the file and restart the Home Assistant app on RunTipi.
Step 4: Setting Up HomeKit Integration
In Home Assistant, go to Configuration > Integrations.
Add a new integration and search for “HomeKit”.
Follow the prompts to set up the HomeKit integration.
Once complete, you’ll see a QR code or a pairing code.
Step 5: Pairing with iOS Device
Open the Home app on your iOS device.
Tap the “+” button to add a new accessory.
Scan the QR code or manually enter the pairing code provided by Home Assistant.
Wait for the connection to be established. This may take a moment.
Troubleshooting
If you encounter issues:
Ensure all ports are correctly forwarded and not blocked by firewalls.
Double-check that the mDNS repeater is running correctly.
Verify that the HomeKit integration in Home Assistant is using the correct port (21063).
If using Tailscale or other VPN solutions, ensure they’re not interfering with local network discovery.
Conclusion
By following these steps, you should now have Home Assistant successfully integrated with HomeKit through RunTipi. This setup allows you to control your smart home devices using Apple’s Home app and Siri, providing a seamless experience across your Apple devices.
Special mention & Massive shout-out to jigsawfr from Runtipi discord for helping me set it up for the first time!
Initially software was bought and sold in CDs. If you bought a copy of windows 7, you’ll get a windows key along with the CD. And you could use the key along with the CD and you owned the software. No recurring subscriptions etc.. Later on if Windows 8 comes up, you would have to go and get the upgrade.
The reason this is great is because there is one simple predictable pricing structure & clear ownership.
This is fundamentally different from leasing software with subscriptions. Any software without significant recurring cost should IMO offer a single time license. They can always say that the upgrade needs to paid for. But the version of the software you bought is with yours. Even if the company dies.
This is a list of software vendors who support this kind of payment options. They either offer a way for me to buy software and own that version of it or do a lifetime purchase for the service itself.
The organization can have its own universe of self hosted & well designed tooling which solves these problems really well.
More importantly, self hosting is deemed to be too scary. I disagree. Its actually very much doable with the current compute speeds and docker based backups.
Companies should give it a honest shot at a small scale to start with and see how it goes.
Let’s say you want to download Sintel, the creative common licensed movie made in Blender from torrents.
There are a couple of options for downloading torrents on your Tipi. We’ll use Transmission for now.
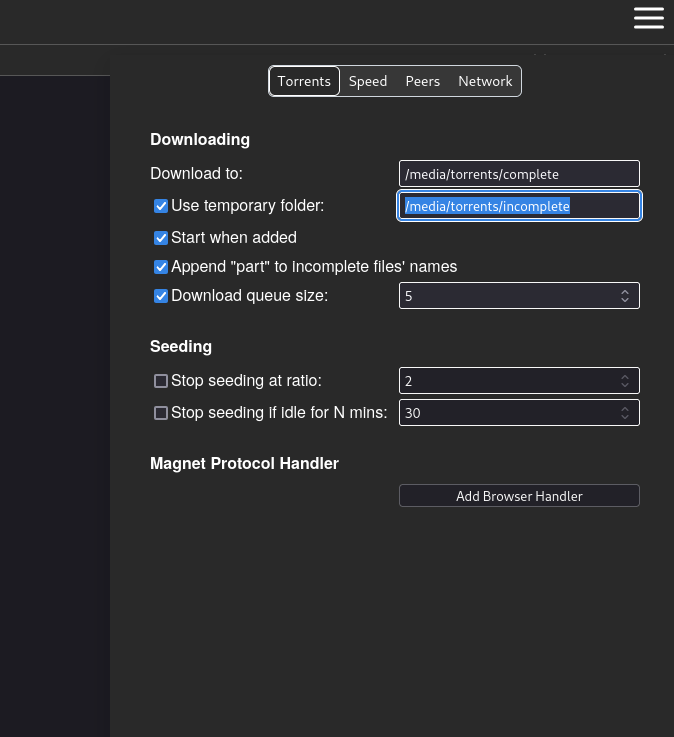
Understanding the folder structure
Tipi mounts folder /media/torrents for transmission to write into. Usually people prefer incomplete downloads to be placed in /media/torrents/incomplete & /media/torrents/complete for complete downloads.
Permissions
Make sure ~/runtipi/media/torrents is owned by user 1000. For this, ssh into your server and do ls -al ~/runtipi/media and see if the owner is user 1000. If not, run
sudo chown -R 1000 ~/runtipi/media/torrents/
The above should be automated in the install step on Tipi later on, this is temporary.
Setting good defaults
Go to settings in transmission
Set Download to /media/torrents/complete & temporary folder to /media/torrents/incomplete.
This will make sure torrents download to the folders shared with Tipi.
You can later move the file to ~/runtipi/media/data/movies or ~/runtipi/media/data/music using an app like filebrowser.
That’s it! Apps like Jellyfin have access to ~/runtipi/media and you should be able to watch it on your Tipi instance.
How much time does it take for you to go from imagining a decent idea to having a functional bare bones proof of concept web app?
Right now, for me it’s around two days of intermittent work. Here’s why
My current stack is
Next js for the back end and SSR
mongodb as the database
Tailwind as the css framework
Firebase as the auth provider
Prisma as the orm most of the time (or mongoose if I’m with mongodb)
Some kind of redux alternative if needed
And the list goes on.
I waste the most amount of time on
Authentication: the firebase/ auth0 integrations of the world
Deciding on the db
Deciding on the front end framework
Spending a stupid amount of time on styling and css libraries
This is pretty disappointing. Idea to go live should be as soon as possible so that iteration speed is great. What’s the point of having insane tech at our disposal if we still struggle to do basic crud apps slowly?
How to move faster on side projects?
There are three common answers to this from the community I hear
Php and friends: larvel seems to be pretty good
Ruby on Rails : one of the most beloved frameworks for developing web apps. Apparently once you get it, there is no going out.
Django: aimed at perfectionists with deadlines. Delivers what it promises absolutely.
There are only two options, in my opinion, that absolutely stand out right now. One is called PhotoPrism, and the other is called Immich.
As I mentioned before, I run a modest Chrome Box as a home server. I’ve always wanted to move away from iCloud because it becomes expensive rather quickly, but I couldn’t find a solution that also offered a great user experience.
I initially started with Immich, ran it once, and it crashed my server. I then migrated to PhotoPrism, which was more efficient, but the UI wasn’t great.
After a few days, I switched back to Immich. I hoped I could make it work by disabling many options, and I was right. After completely disabling machine learning and video transcoding, Immich seems to be okay, although it still consumes a significant amount of CPU and heats the server.
But as of now, there’s nothing else like it on the market, and this is the best we have. I hope they optimize the performance and eventually provide tips on disabling heavy features during installation, which would make the onboarding process easier. To be fair, Immich isn’t even at version 1.0 yet—it’s still considered beta software. For a beta, it’s extremely well-polished, so kudos for that.
My recommendation would be to go with Immich, but carefully go through the settings to ensure you’re disabling any unnecessary or resource-intensive features.
The rest of the article is a more formal analysis of the pros and cons.
PhotoPrism
Pros:
Does not disturb the external library, making it very easy to migrate and maintain.
Machine learning for face detection.
Cons:
No Android or iOS app.
The UI could be more polished.
User management UI is not included in the free version.
Immich
Pros:
Excellent Android and iOS apps.
Beautiful UI.
Machine learning for face detection, etc.
Implementation of configuration for custom use cases.
Great administration UI, including views on jobs running, active, waiting, etc.
Cons:
If you run a lighter home server and forget to disable machine learning and video transcoding features, it will push the CPU to 100% consistently. Some feature flag management at the setup level would be helpful to prevent this.